Taking you one step ahead
High availability with Etherchannels
Today's topic is all about redundancy. Well, at least, in a way. Redundancy is a great thing, although it's not how it's always been. We're focusing on ethernet today, ethernet topology to be precise and how it plays an important role in availability and reliability.
Traditionally, when we migrated from coax to UTP we also migrated from the bus topogloy to star or tree topology. The focus here is not on the tree or the star, but on the one thing they have in common. There is only one path between any two given points. In another way: if nodes are vertexes and the connectivity between them are the edges, there are no loops in this grap. This is very important and it always has, before the smart people invented STP - Spanning Tree Protocol.
We're not here to talk about STP today, we must mention the existence and why it plays a vital part in redundancy. Imagine a simple network with several links without a loop. A packet introduced into the topology will travel through all links while getting towards the leafs or endpoints. These are stations on the network. Once the stations have processed the packet all, some or none of them will react. The original packet may or may not trigger new packets to be created by the stations. These new packets will travel through the links again and at some point the communication will stop, no packets will be on the network and all links will be idle. At least for some time until the next packet is introduced into the network.
This is how loop-free topologies work. Change one bit now: introduce a loop into the network. Given that nothing else has changed, you have now created a very dangerous environment in which (when certain circumstances have met) an endless packet flow can be present. In such environment it is very easy to bring the network to its knees, simply, because the number of packets to be transmitted quickly escalate to above and beyond the capabilities of the network. By this, imagine the number of packets (frames) need to be transferred from one wire to another. This is obviously a limited number. Within three seconds, you can create the M25 of networks: a topology that is not capable of handling the load and all packets (or in our metaphor: cars on the highway) are coming to a full stop and nothing moves anymore.
This is simply because frames are epxected to be seen once on a network, and if the same frame somehow gets around, it is treated as if it was never there before. For this very reason, ethernet topologies have been treated strictly loop-free topologies. Until STP came into the picture. In a nutshell, because we're still not here to discuss STP, this protocol is capable of handling the presence of redundant paths or loops. Loops suddenly became famous. In the old days when something broke (node or a connection) it had a massive impact on the network and there usually was a big outage. And it remained like that until the network guy fixed it. STP made it possible to have alternate links present at all times, but the protocol made it invisible for the network under normal operating conditions. So it appeared to the network as if those redundant links (causing a loop) were never there. But when something broke, suddently STP brought these links back and the topology was immediately fixed.
It's a clean and neat protocol, with two problems. One: it takes time to recover from a faulty condition. It may be a short period of time, but still, it can last up to 30 seconds. Two: you are building redundant paths into your network, which in normal conditions are never used. They consume power, switch port, cables and they aren't scalable. Worst case scenario: you double each and every single link in your network. You end up being completely redundant, which is a good thing. But also, you have twice as many cables, switch ports, air conditioning, rack space and cost as you would normally need. And for what? To have 50% of your network infrastructure sit idle 7/24. Because that's how STP operates. How about a fail-safe solution where the links can actually be utilised? Where they don't sit idle for most of the time? Well, meet Etherchannels.
Etherchannels are called various names on different plaforms. They term etherchannel, port channel, bonding, teaming usually all mean the same. Similar to STP, etherchannels need the devices on the two ends to agree on things for the whole thing to be functional, and you can look at etherchannel as simply having a wider motorway. Imagine the traffic on a crowded motorway where each side has 2 lanes. Everyone is standing still. Add two more lanes to each side, now you have 4 lanes going each way. Things ease up a bit. Now add four more lanes, having a total of eight each way. This moving pretty fast now. This is exactly what etherchannel is. Add some redundant links but instead of using them in an active-passive way (remember, STP makes it invisible for the network to avoid loops), use them in active-active setup. Basically the devices are told to treat several parallel links as one logical. Therefore no loops, because the parallel links are not individual links. They are a physical representation of one big giant cable. Because it is treated like one logical cable - there is no loop. But when a failure occurs, simply take away some links and use the remaining ones. Less traffic will be able to go through, just as when a couple of lanes are closed off for maintenance. The road is still open, but it has a thinner capacity. As long as at least one lane is left open, the road is operable, so is the network connectivity. It will be slower, but it will be there.

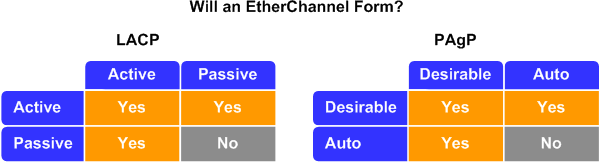
Etherchannels are a brilliant idea. So brilliant, more than one person came up with the idea. Cisco did, of course, and they version is called PAGP. It is propietary, so everyone else came up with the idea of LACP, which is an open standard. Cisco kit speaks both. It doesn't really matter which one you choose, as long as you choose the same on both ends of the cable. PAGP stands for Port Aggregation Protocol, LACP is Link Aggregation Control Protocol. The name is different, but the goal is the same. Talk to your neighbour, agree on some principles and off we go. Superhighway of internetworking. It's so good, it's almost too good to be true. There must be a catch. Well, sort of. Etherchannel has its lmitations. It can operate in many modes, and not all of them mean it works right away. Take a look at the diagram below which details the modes of operation, and shows you in which modes will the etherchannel form. As you might have guessed already: PAGP and LACP is not compatible, although they are to achieve the same thing.
Before we look into limitations, let's just see how it operates in detail, so we can fully understand the concept. The key is to be able to utilise traffic efficiently on multiple links. By default, Cisco switches do a (source IP) XOR (destination IP) algorithm, which is usually fine. Except when it's not :) Such case can be when the etherchannel is not used in the core layer (remember those layers?) but in distribution, or even in access layers. Where mostly the same traffic will pass through the link. Like when you do an etherchannel between a server and a switch. This is a perfectly valid configuration and it will work - as long as both the switch and the server support the same set of protocols. It not only enhances availability, but also gives a higher bandwidth to use. This is not a bad thing in case of a server. You have four 1Gbit/s ethernet interfaces, and you make them one big 4Gbit/s interface. Quite impressive actually, this is something that makes project managers happy.
But back to algorithms. The above is a default, you can load-balance traffic based on MAC addresses (source and destination) IP addresses (as mentioned above) or even TCP/UDP port numbers. And this is all done in hardware. Choose your algorithm wise, as for example a web server whose IP or MAC address won't change, and traffic will be always coming from port 80 is not a good candidate for destination IP/MAC/port address based load balancing. You'll end up having all the traffic on one link, and the remaining ones unused. A valid question might be: do I have to send traffic back on the same link where it came from? No, you can have different choices on each side. Being asymmetrical is a good thing. Also, keep in mind that PAT can screw things up. Suppose you have a port channel in the core layer, just after you've performed the actual address translation. By using the default Cisco algorithm, if most of your users are targeting the same IP address on the same protocol (such as a company web portal that is the default home page in every browser) it is likely that all of your traffic will use the same link, instead of being distributed. This is because source IP will remain the same (PAT), destination address will also be the same, and the destination port number as well. A good command to experiment with is the test etherchannel command. Go ahead and start studying the online help, as it's quite useful. This command helps you to understand what hash value will be computed for a given traffic flow and as a result, which link will be used to send out the traffic.
Here are some tips to build/plan a good etherchannel. Maintain an even number of links in a port channel and do monitor each of them using a designated software. Such software comes handy in all cases and you can get them for free. The most popular is probably Cacti, which is an mrtg/rrdtool frontend and is quite good at it. The even number of links is important, otherwise you may not end up what you hoped for. Having three links in an etherchannel is probably not giving you 33% utilization each. You'll end up 50% for the most used, and 25%-25% for the other two. This is because for three links you need two bits of a hash, giving four possible outcomes (00, 01, 11, 10). But you only have three links. Do not forget to monitor the individual links during peak time, and don't be afraid to change the load distribution algorithm to find the best that suits your traffic flow.
Now, back to limitations. As you may see, we have eliminated the possible downtime caused by a link failure. We still haven't eliminated the possible downtime caused by a switch failure. There is no point having two links if they go to the same switch, is there? A logical next step would be to connect two server NICs to two separate switches and have the port channel there. So if one switch dies, the other still can handle traffic. Unfortunately this is not that simple. On Catalyst switches, a port channel can exist only within the switch itself. This however can be a bit flexible. One solution could be a modular switch, and have the port channel members terminate on different modules. Although it is still the same switch chassis, at least you have the members on different linecards (for example one member on Gi 1/1, the other on Gi 2/1). Because it's the same chassis, etherchannel can be expanded across linecards and if one linecard dies, the other is still capable of maintaining the port channel and passing traffic. But it's still just one switch. Another way of doing port channels is to have what is called a switch stack. Several switches can coexist in a switch stack, in which several different switches form one big logical switch, and operate as one. This can come quite handy, and a port channel can also expand to several switches - because they all form one logical chassis. This can help circumvent the problem. But this is not the real deal. The real deal exists in Nexus environment and is called VPC.
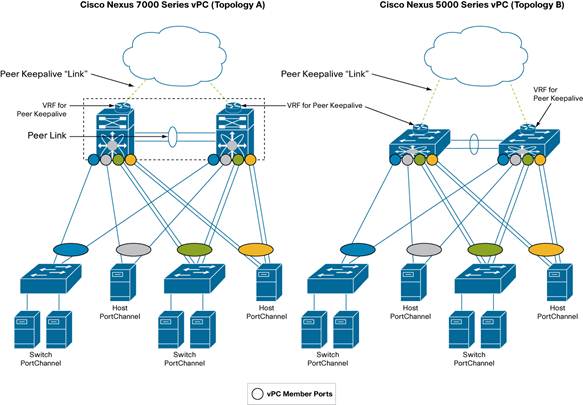
VPC stands for Virtual Port Channel and is what it sounds: one virtual port channel amongs different switches that can operate on their own, but still share port channel information between them. This is what real datacenters use, it's the big guy stuff. From the other side's point of view, the two links appera to be coming from the same switch, but in reality, they come from different switches. This neat feature is only implemented on Nexus 5k and 7k series, so be prepared to spend tens of thousands of british pounds to spend. It's not going to be cheap :). Take a look at the following diagram (which is taken from the official Cisco documentation) and it all becomes quite clear. Note the peering link between the individual switches, where they share etherchannel information, this makes the whole thing possible. Note how several uplinks point to different switches, thus making the whole design more robust and reliable.
- Log in to post comments